
¿Cómo pueden los avances en Inteligencia Artificial ayudar a aquellos que necesitan aprender Lengua de Signos?
Esta historia comenzó en Madrid, España. Se acercaba el invierno y un equipo de cuatro jóvenes entusiastas comenzamos un proyecto.
La idea inicial era crear una aplicación para aprender la Lengua de Signos, no solo porque es un aspecto interesante de nuestra sociedad, sino también para aquellos 34 millones de niños con pérdida de audición discapacitante que necesitan aprenderla para comunicarse.
La belleza de la tecnología es que también puede usarse para ayudar a otros. Nuestro objetivo era hacer exactamente eso.
La idea principal era construir un modelo de redes neuronales capaz de clasificar, a partir de las imágenes capturadas por una cámara, las representaciones de signos que el usuario hiciera, en tiempo real. Este “usuario” podría ser un niño aprendiendo en casa la lengua de signos o reforzando lo que le han enseñado en la escuela, o puede ser un adulto interesado en aprender desde cero, por ejemplo, para empezar, las letras del alfabeto o los números.
Los Datos
En cada proyecto relacionado con datos, como el nuestro, una parte esencial del trabajo es encontrar un conjunto de datos suficientemente bueno para que el modelo pueda realmente aprender. Sin datos, ni siquiera podríamos comenzar a tratar de construir un modelo que fuera capaz de comprender qué signos estaba haciendo el usuario frente a la cámara.
Como somos de España, lo primero que pensamos fue desarrollar la aplicación para la LSE (Lengua de Signos Española). Pero la investigación y la innovación no es un camino de color de rosas. No pudimos encontrar ningún dato relacionado con el alfabeto español, ni en Internet, ni siquiera escribiendo a entidades que pudieran tener esta información. Así que tuvimos que tomar la decisión de utilizar los datos que sí aparecían en varios sitios: la lengua de signos americana.
Comenzamos a explorar en una etapa inicial las letras del alfabeto y los números del cero al nueve. Luego, tuvimos otro problema. La aplicación tal y como se pensaba desde el principio se basaba en la construcción de una red neuronal profunda que pudiera clasificar los signos a partir de imágenes estáticas. Este hecho creó un problema con las letras que tenían movimiento: la J y la Z. Nuestra decisión para la primera versión básica fue abandonar esas dos letras por el momento.
Los datos que encontramos sobre las letras y los números fueron en realidad imágenes de manos de personas, tomadas de Kaggle, un repositorio ampliamente utilizado en nuestra comunidad.
El Modelo
La segunda etapa fue entrenar a un modelo para que fuera tan inteligente que cuando viera la imagen de un signo pudiera identificar cuál era. Comenzamos con una red neuronal convolucional (CNN) con varias capas convolucionales, max-poolings, flatten y fully connected. Pero aprendimos con la experiencia que incluso si la precisión de la validación era alta y la pérdida de validación era baja, lo más importante era el rendimiento en tiempo real, con nuestra cámara, con diferentes manos y diferentes fondos detrás de las manos. Y no obtuvimos un buen resultado.
Fue entonces cuando decidimos aprovechar un modelo previamente inteligente, una CNN profunda capaz de clasificar objetos a partir de imágenes, la VGG19 entrenada con ImageNet.
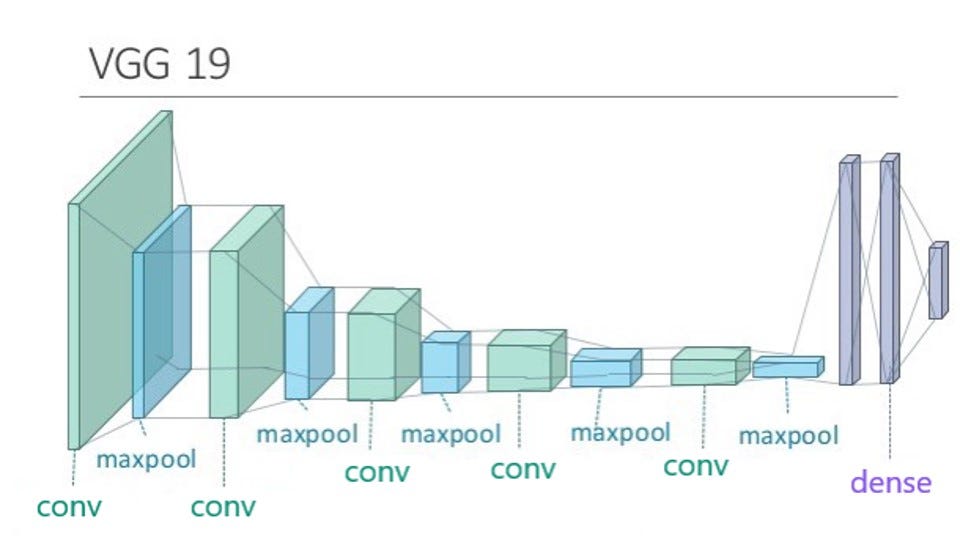
ImageNet es una gran base de datos con más de 14 millones de imágenes que contiene más de 20000 categorías y en la versión recortada 1000 clases. Muchos modelos han sido entrenados con este conjunto de datos, llegando a ser capaces de comprender partes muy abstractas y creativas de las imágenes. Teníamos que aprovechar estas características. Este proceso se conoce en la comunidad como “Feature extraction”. Simplemente era tomar un modelo previamente entrenado sin las capas superiores, congelar el modelo, agregar nuestras capas superiores especificando cuántas clases queríamos clasificar y reentrenarlo con nuestro conjunto de datos. Esa parecía ser una buena idea, pero de nuevo, la experiencia en tiempo real, no fue tan buena como queríamos que fuese.
Así que dimos un paso atrás y meditamos la idea del modelo pre-entrenado. El conjunto de datos de ImageNet con el que se entrenó VGG19 no contenía clases de manos desnudas, ni representaciones de lengua de signos. Lo que estábamos tratando de hacer era forzar a una red a clasificar algo cuando era básicamente inteligente para clasificar otras cosas del mundo, excepto las manos.
Fue entonces cuando decidimos hacer “Fine tuning”, otra técnica muy utilizada en Deep Learning. Decidimos congelar solo las primeras 6 capas de VGG19 y reentrenar todas las demás, junto con nuestras capas superiores con nuestro conjunto de datos.
Por otro lado, pero al mismo tiempo, los datos estaban pasando por varios cambios. Nos dimos cuenta de que el conjunto de datos inicial era demasiado pobre, luego nos propusimos la tarea de obtener imágenes con nuestra propia cámara, las mezclamos con el conjunto de datos inicial y usamos esa mezcla de imágenes para configurar un Image Data Generator que incluyera algunas transformaciones como recortes, desplazamientos, etc.
Con estos dos ingredientes mezclados en nuestro cóctel, un conjunto de datos muy sólido y un modelo súper inteligente, solo esperábamos buenos resultados. Y los tuvimos.
https://www.youtube.com/watch?v=s0JffO7ubywEstamos abiertos a recibir comentarios sobre nuestro trabajo inicial, porque actualmente lo estamos desarrollando para una mejor aplicación futura que realmente pueda ayudar a otros. También tenemos el código abierto en GitHub en este enlace:
Sign-language-translator-python-opencv
Somos Elisa Cabana (Twitter), Jessica Costoso, Jordi Viader (LinkedIn) y Miguel Gallego (GitHub), con la ayuda de Carlos Santana (Youtube). Esperamos que algún día la tecnología se use para eliminar los obstáculos del camino de aquellos que necesitan nuestra ayuda, porque una barrera para algunos es en realidad una pérdida para todos.
Aprovecha los descuentos de hasta un 95% en todos mis cursos, solo por 9.99€
Sígueme por mis redes sociales:




